
影刀编码版实现异步 + 多线程并发处理:大规模下载链接
#适用场景#很多用户需要下载大量的图片或是视频,目前影刀内部指令只支持异步下载图片,如果有其他压缩包或者视频的需求那么就可以用到这窜代码去并发下载其他类型的文件啦。#使用截图##参数说明#1.url_list:用于传入下载链接的列表2.download_folder:传入文件下载的文件夹地址(若文···...
扫码分享二维码
#适用场景#很多用户需要下载大量的图片或是视频,目前影刀内部指令只支持异步下载图片,如果有其他压缩包或者视频的需求那么就可以用到这窜代码去并发下载其他类型的文件啦。#使用截图##参数说明#1.url_list:用于传入下载链接的列表2.download_folder:传入文件下载的文件夹地址(若文···...
扫码分享二维码
#适用场景#
很多用户需要下载大量的图片或是视频,目前影刀内部指令只支持异步下载图片,如果有其他压缩包或者视频的需求那么就可以用到这窜代码去并发下载其他类型的文件啦。
#使用截图#
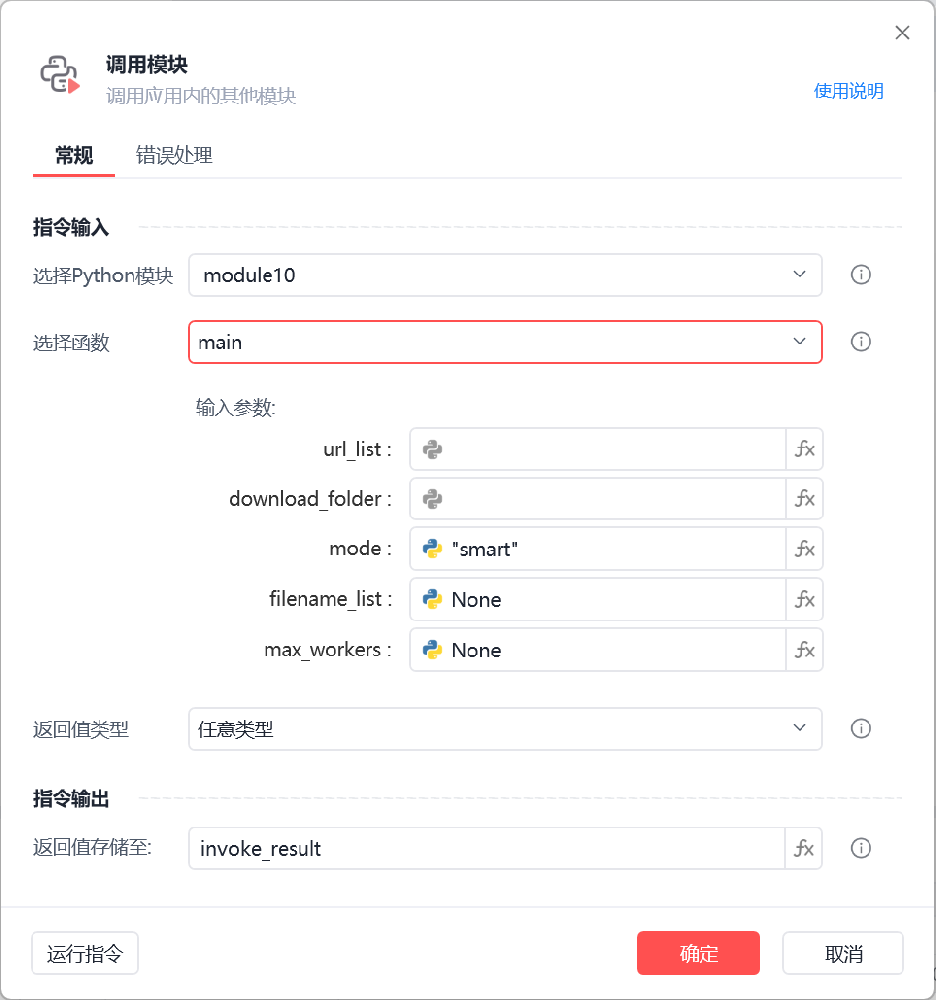
#参数说明#
1.url_list:用于传入下载链接的列表
2.download_folder:传入文件下载的文件夹地址(若文件夹不存在会自动创建)
3.mode:下载模式分别有smart,fast,ultra,async四种模式
4.filename_list:可不填,用于给下载下来的文件列表命名,比如:0.mp4,1.jpg等等,默认为None则自动以0,1,2,3,4命名,文件后缀会自动识别
5.max_workers:最大线程数,选填,默认为None,不同模式会自动选择不同线程数,后续会细讲。
#Mode解说#
mode中分为以下四种模式:
•smart:通过计算自动评估文件数量选择最优线程
•fast:固定使用20个线程
•ultra:使用高并发60线程(CPU线程数要求较高,普通电脑不建议用)
•async:真异步下载(虽然快但是对服务器要求较高,非服务器/工作站还是手动更改一下max_workers的线程数吧)
#附上源码#
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import os
import time
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
import asyncio
import aiohttp
from aiohttp import TCPConnector
# -------------------------------------------------------------------
# 基础下载函数
# -------------------------------------------------------------------
def download_file(url, filename, download_folder, session, retries=3):
""" 单个文件下载(精简版,无进度条) """
for attempt in range(retries):
try:
response = session.get(url, stream=True, timeout=30)
response.raise_for_status()
os.makedirs(download_folder, exist_ok=True)
file_path = os.path.join(download_folder, filename)
with open(file_path, "wb") as f:
for data in response.iter_content(chunk_size=65536):
if data:
f.write(data)
return True
except Exception as e:
if attempt < retries - 1:
time.sleep(2 ** attempt)
else:
print(f"下载失败:{filename} - {e}")
return False
# -------------------------------------------------------------------
# 多线程下载
# -------------------------------------------------------------------
def multithread_download(url_list, filename_list, download_folder, max_workers=20, retries=3):
if not url_list:
print("没有可处理的 URL。")
return
print(f"开始多线程下载,共 {len(url_list)} 个文件。")
success = 0
fail = 0
with requests.Session() as session:
session.headers.update({"User-Agent": "Mozilla/5.0"})
with ThreadPoolExecutor(max_workers=max_workers) as ex:
tasks = {
ex.submit(download_file, url_list[i], filename_list[i], download_folder, session, retries): filename_list[i]
for i in range(len(url_list))
}
for future in as_completed(tasks):
if future.result():
success += 1
else:
fail += 1
print(f"完成。成功 {success} 个,失败 {fail} 个。")
# -------------------------------------------------------------------
# 异步下载
# -------------------------------------------------------------------
async def async_download_one(session, url, filename, download_folder, semaphore):
async with semaphore:
try:
async with session.get(url) as resp:
resp.raise_for_status()
os.makedirs(download_folder, exist_ok=True)
path = os.path.join(download_folder, filename)
with open(path, "wb") as f:
async for chunk in resp.content.iter_chunked(65536):
f.write(chunk)
print(f"完成:{filename}")
return True
except Exception as e:
print(f"失败:{filename} - {e}")
return False
async def async_download_batch(url_list, filename_list, download_folder, max_concurrent=80):
print(f"开始异步下载,共 {len(url_list)} 个文件。")
semaphore = asyncio.Semaphore(max_concurrent)
connector = TCPConnector(limit=max_concurrent)
timeout = aiohttp.ClientTimeout(total=300)
async with aiohttp.ClientSession(connector=connector, timeout=timeout) as session:
tasks = [
async_download_one(session, url_list[i], filename_list[i], download_folder, semaphore)
for i in range(len(url_list))
]
results = await asyncio.gather(*tasks)
success = sum(1 for r in results if r)
print(f"完成。成功 {success} 个,失败 {len(url_list) - success} 个。")
def run_async(url_list, filename_list, download_folder, max_concurrent=80):
asyncio.run(async_download_batch(url_list, filename_list, download_folder, max_concurrent))
# -------------------------------------------------------------------
# 智能模式
# -------------------------------------------------------------------
def calculate_optimal_workers(file_count, max_workers=100):
if file_count <= 10:
return min(5, file_count)
elif file_count <= 50:
return min(20, file_count)
elif file_count <= 100:
return min(40, file_count)
else:
return min(max_workers, file_count)
def smart_download(url_list, filename_list, download_folder):
file_count = len(url_list)
workers = calculate_optimal_workers(file_count)
print("智能模式")
print(f"文件数量:{file_count}")
print(f"推荐线程数:{workers}")
multithread_download(url_list, filename_list, download_folder, max_workers=workers)
# -------------------------------------------------------------------
# 主调度函数
# -------------------------------------------------------------------
def main(url_list, download_folder, mode="smart", filename_list=None, max_workers=None):
if filename_list is None:
filename_list = []
for i, url in enumerate(url_list):
ext = os.path.splitext(url)[1] or ""
filename_list.append(f"{i}{ext}")
print("任务启动...")
if mode == "smart":
smart_download(url_list, filename_list, download_folder)
elif mode == "fast":
multithread_download(url_list, filename_list, download_folder, max_workers=max_workers or 20)
elif mode == "ultra":
multithread_download(url_list, filename_list, download_folder, max_workers=max_workers or 60)
elif mode == "async":
run_async(url_list, filename_list, download_folder, max_concurrent=max_workers or 100)
else:
print("未知模式,将使用智能模式。")
smart_download(url_list, filename_list, download_folder)#安装PYTHON库#
pip install aiohttp
pip install requests
以上内容来源于影刀社区【huanwodianfanbao】坛友分享
Copyright Notice
当前文章由【付涛】本人原创开发与文案内容写作,内容版权归当前平台所有,如需转载,请务必注明来源及链接,谢谢合作!
本文最后更新发布于【2025-11-19】,某些文章具有时效性,若有错误或已失效,请联系客服
争议处理:针对本站内容若有异义,亦可直接与【法律顾问:易兴俊,律师联系电话:13825799821】直接联系沟通